Hello everyone!
It’s time for another long-overdue update on how Fedecan and our various sites are doing. It’s been just over two years since the great Reddit migration, and in that time we’ve made some solid progress:
- Registered Fedecan.ca as a non-profit
- Moved from OVH to our own hardware in a Vancouver datacenter
- Started collaborating with the team behind sh.itjust.works
- Launched Pixelfed.ca
- Launched Piefed.ca
Finances
Here’s a look at our bank balance since we began accepting donations:

We’re currently sitting at around $2,900, with a monthly burn of about $200, which gives us roughly a year of runway. We have some additional annual costs (like domain renewals and non-profit registration), but overall we run very lean.
Fedecan still owes:
- TruckBC: $1,980
- Shadow (me): $525
These were out-of-pocket hosting and non-profit registration costs from 2023/2024. It’d be great to get those covered, but we want to keep at least a year of operating expenses in reserve.
If you're a regular user and value what we're doing, please consider donating! We have multiple ways to donate, you can find the comparison and donation links on our website: https://fedecan.ca/en/donate
Sh.itjust.works
Nothing major to report here - we’ve all been a bit busy lately, but collaboration is continuing slowly behind the scenes.
Fediverse Growth
We're seeing a healthy volume of posts and communities on lemmy.ca, surging with each Reddit drama:

Infrastructure
Our server is a Dell R7515 with an EPYC 7763, 1 TB ram and 4x 7.68tb nvme data disks, which is hosted in a datacenter in Vancouver, BC.
I spun up victoriametrics + victorialogs a few weeks ago and have been ingesting all of our data, giving us the ability to put together some nice grafana dashboards.
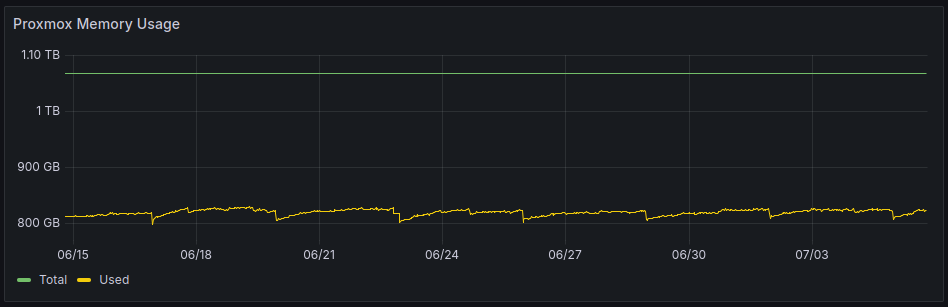
Everything is running great on the infrastructure side of things. Our server is barely working up a sweat and we shouldn't have to worry about scaling for a long time.

Lemmy.ca still comprises almost all of our traffic:

Lemmy.ca
Our over provisioned stack is performing well, handling the occasional lemmy / lemmy-ui dropout:






Similarly the DB is mostly running out of ram:

Our object storage is slowly climbing as expected, but we've got several years of capacity to figure out a long term solution:

I’m also doing some limited analytics on our web logs. As expected, lemmy.world makes up the majority of our federation traffic:

One interesting thing to see from the user-agent data is the breakdown of traffic by the different mobile clients:

The “dart” UA is just a common web library, Thunder reports as this and I suspect other clients do too. If you’re a client developer, please set your user-agent!
Out of the alternative web clients we support, tesseract is the most popular although the overall traffic volume is still low:

We only store 7 days of logs but I’m hoping to get these pulled out into metrics soon, since it would be interesting to track which clients / interfaces people use over time.
Pixelfed.ca
Not much to say on this one, due to using local storage it currently runs on a single VM without redundancy.


Piefed.ca
Piefed runs on a pair of VMs with its own database and object storage backends.


Cloudflare
If you want to compare against previous data posts, here’s our same cloudflare graphs for lemmy.ca

As always, feel free to reach out if you have any questions or ideas. Thanks for being a part of the Fediverse!


https://en.m.wikipedia.org/wiki/Burn_Cycle maybe