WSJ lied (or misrepresented information), probably to manipulate the stock market.
P.S. In case you didn't already know: don't try to engage in serious conversations about ML on awful.systems, it will always end up exactly like this one.
WSJ lied (or misrepresented information), probably to manipulate the stock market.
P.S. In case you didn't already know: don't try to engage in serious conversations about ML on awful.systems, it will always end up exactly like this one.
As stupid as that sounds, you are not totally wrong.
@[email protected] and @[email protected] you are misunderstanding what "observable universe" means. The observable universe is defined by the particle horizon, but the universe that can affect us in the future is defined by the event horizon. https://en.wikipedia.org/wiki/Cosmological_horizon says
The particle horizon differs from the cosmic event horizon, in that the particle horizon represents the largest comoving distance from which light could have reached the observer by a specific time, while the cosmic event horizon is the largest comoving distance from which light emitted now can ever reach the observer in the future.
But even the cosmological event horizon distance is dependent on our model of the universe's expansion, which in turn depends on the content of the universe. An event such as a vacuum collapse will drastically alter the content and the expansion rate, rendering our calculation of the event horizon invalid. So "snap changes..." may in fact be the case.
It kinda works you just gotta be careful with what you use and keep some human in the loop curating the outputs.
This meme was about training on model outputs. But would be nice if they got some trade secrets as well. Intellectual property is cancer and these IP-stealing Chinese companies, if they exist, are doing god's work 😊 hope Indian companies steal from China next as well
Did I say OC? I photoshopped the Bloomberg thing on top of someone else's meme that I ~~stole~~ obtained via fair use. It's basically OC by tech companies' standards.

That's why I wanted to confirm what you are using lol. Some people on Reddit were claiming the full thing, when run locally, has very little censorship. It sounds somewhat plausible since the web version only censors content after they're generated.
You're probably running one of the distillations then, not the full thing?
I just really hope the 2023 "I asked ChatGPT and it said !!!!!" posts don't make a comeback. They are low-effort and meaningless.
@[email protected] Wrong community for this kind of post.
@[email protected] Can you share more details on installing it? Are you using SGLang or vLLM or something else? What kind of hardware do you have that can fit the 600B model? What is your inference tok/s?
I think we just differ on the terminology of invention versus observation. What draws the line between a well-supported theory and an observation in the end comes down to how tangible you think the data is.
The ball can quantum mechanically tunnel out to the true minimum. In this sense the local minimum is actually not perfectly stable.
Caption: an interview dialogue
End of caption
Dark matter is the mainstream among physicists, but internet commentators keep saying it can't be right because it "feels off".
Of course, skepticism is good for science! You just need to justify it more than saying the mainstream "feels off".
For people who prefer alternative explanations over dark matter for non-vibe-based reasons, I would love to hear your thoughts! Leave a comment!

CW: Reddit
Originally from https://old.reddit.com/r/polandball/comments/1gg2ifk/eurosummer/
Shark is hai in German and haj (pronounced hai) in Swedish. blåhaj means blue shark.

Tap for spoiler
The bowling ball isn’t falling to the earth faster. The higher perceived acceleration is due to the earth falling toward the bowling ball.


cross-posted from: https://lemmy.ml/post/19504984
It's all relative

cross-posted from: https://hexbear.net/post/3062545
Important history
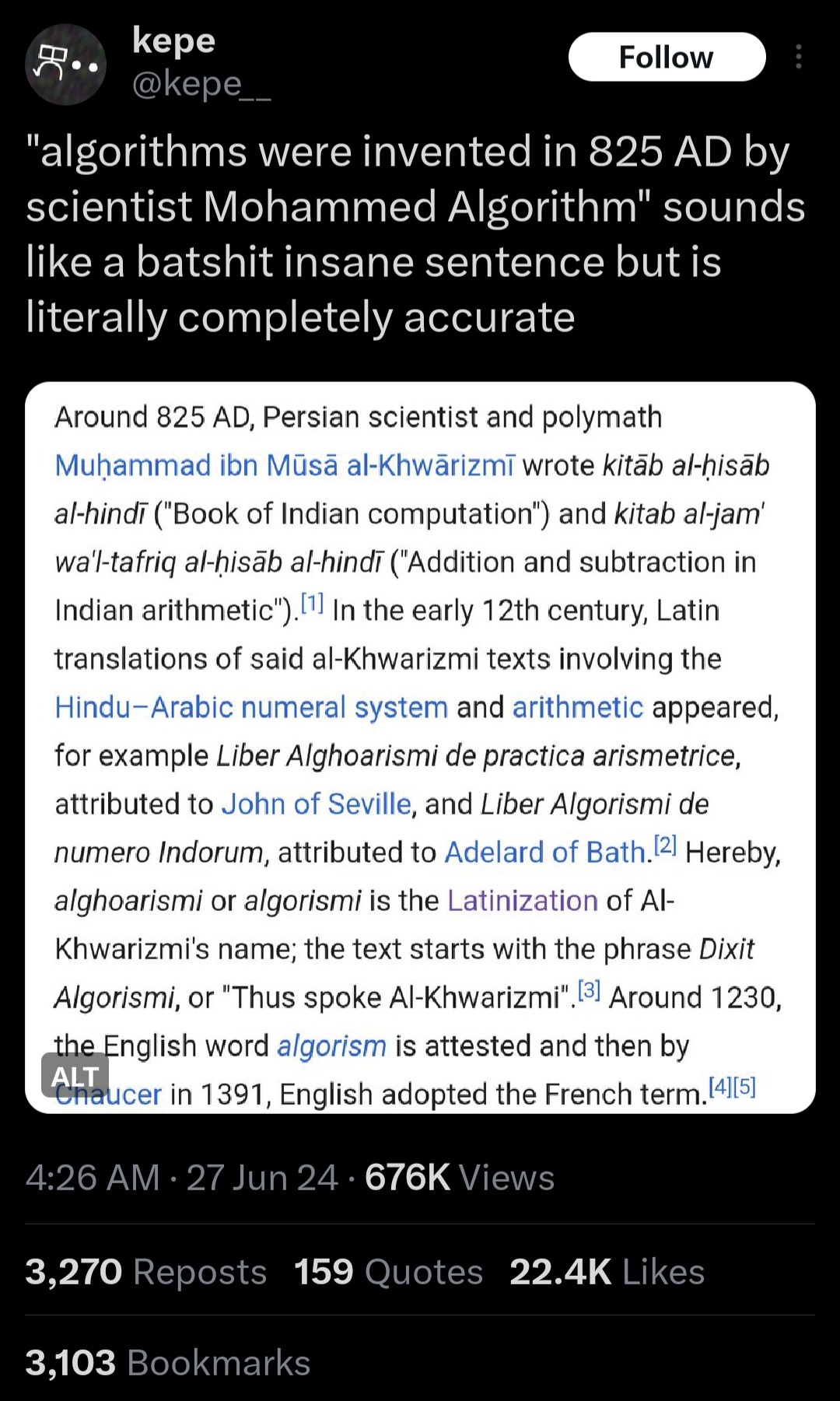
I saw a few math memes so I figure these are allowed here

Doesn't like very important information. Anyway, if you care about privacy you should not be using the official app or API. Go on OpenRouter and use DeepSeek models served by other inference providers with better privacy policies.