Oh man I thought that was the needle, not a toothpick. Suddenly this makes sense.
The toothpick is to provide spacing for the button, then you pull it out as you wrap the thread around underneath it.
Oh man I thought that was the needle, not a toothpick. Suddenly this makes sense.
The toothpick is to provide spacing for the button, then you pull it out as you wrap the thread around underneath it.
Neat. https://rexs.nyc/gallery
It was an art project as part of https://www.mta.info/agency/mta-real-estate/vacant-unit-activation
I've had shit experience with Razer and would never buy their product myself, but many people like them. They recently launched a "gaming" vertical mouse.
https://www.razer.com/ca-en/productivity/razer-pro-click-v2-vertical-edition
We don't blame you for your leader, just don't say stupid maga shit and you'll be fine.
Many people on lemmy just read everything and block subs they don't want, rather than sub to what they do want. Subscriber count might not mean that much.
Neat - https://iocaine.madhouse-project.org/how-it-works/
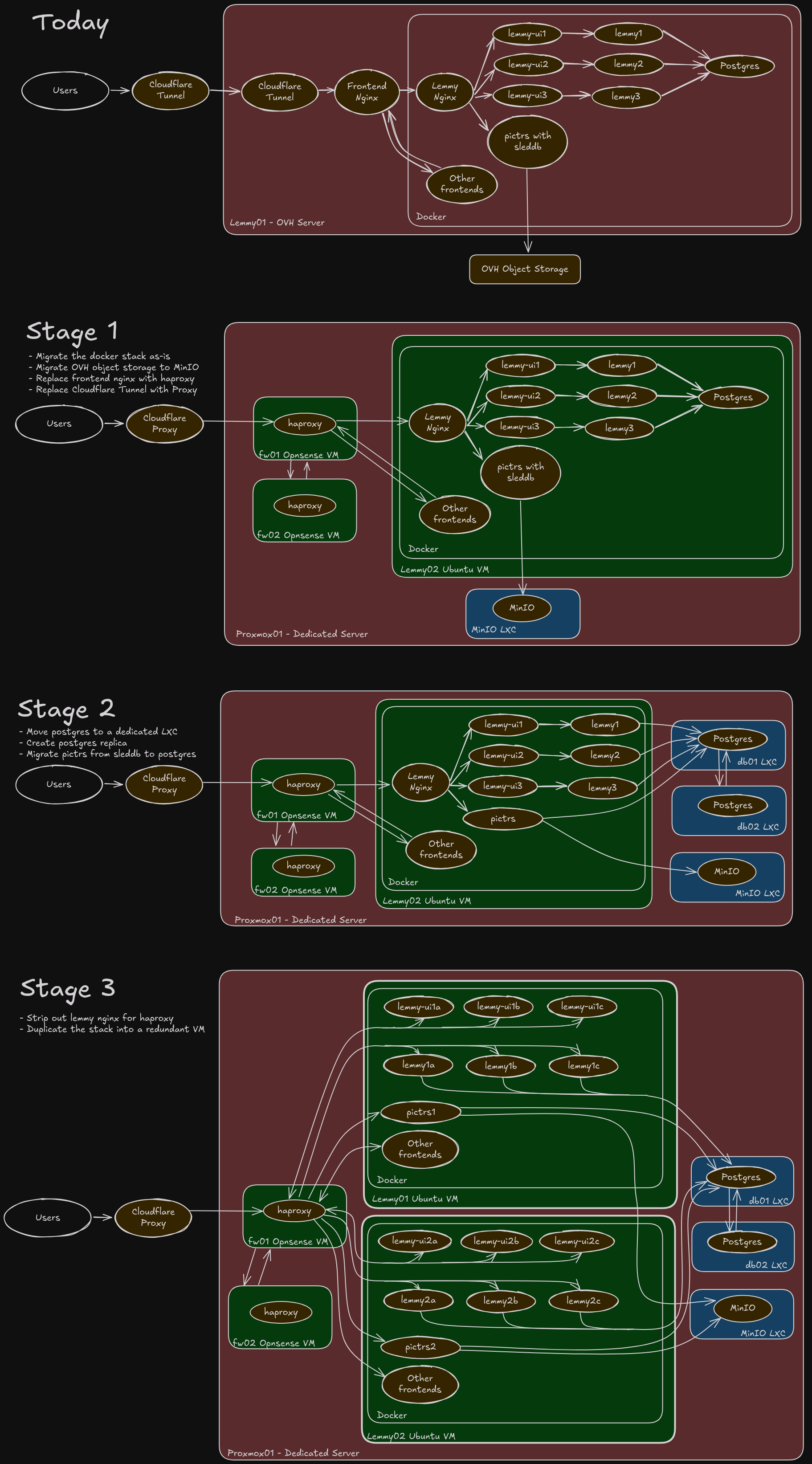
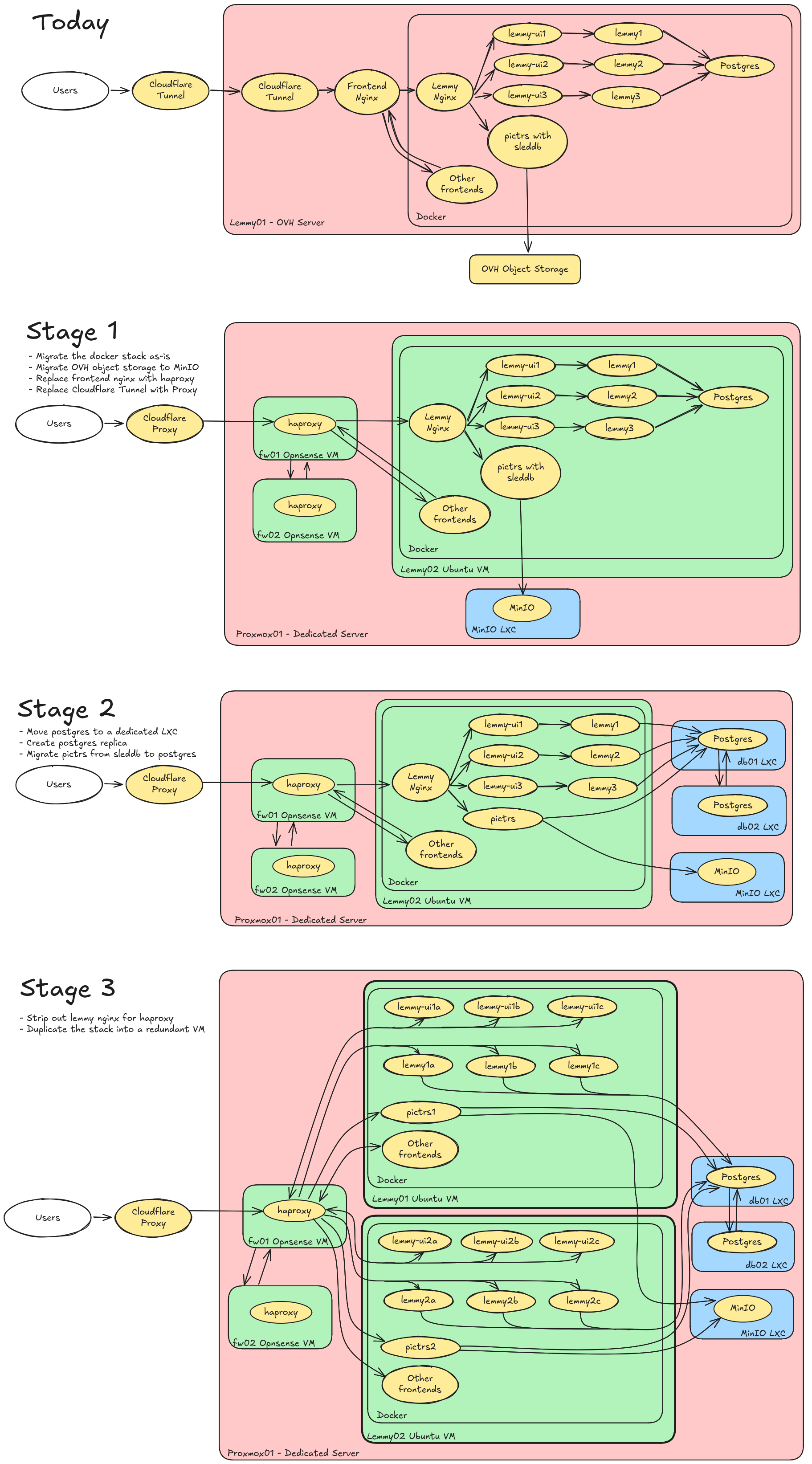
The load wasn't causing any issues, I was just getting ahead of it. I'm not worried about deploying countermeasures yet.
Also see https://lemmy.ca/post/43060353
I might try out anubis on old.lemmy.ca specifically, since bots seem to love it the most
Too many IPs, so I did it by ASN at cloudflare.
There's just no way we have thousands of legitimate but logged out users browsing old.lemmy.ca from their phone in China.
Cloudflare tries, but bots do a pretty good job looking like regular users these days. There's some more advanced "AI" solutions that learn based on existing traffic patterns, but I've been out of that space for a while so not sure what the latest tech is.
I sample every 15s so just multiply the graph numbers by 4
Hmm, I don't think my China blocks did, but I did also turn on Cloudflare's AI bot protection which looks like it did. I've turned that back off now. Sorry about that, thanks for pointing it out!
Unfortunately stats on https://grafana.lem.rocks/d/bdid38k9p0t1cf/federation-health-single-instance-overview?orgId=1&var-instance=lemmy.ca&var-remote_instance=lemmy.world seem to be broken for the past few days.
Yeah I moved off nova to this. It took a bit to get used to it, but now I like it more.
{kind=link}
{kind=link}
Subspace, also known as Continuum later in its life.